- 发布于
- · 更新于 · 约 22 分钟
标签如何在代码里流动——Taint Analysis怎么工作
- 作者

- 姓名
- Morphy Chan
【本文由我与LLM协作完成:想法来自实践,AI参与了文字整理、代码示例和配图生成。】
静态分析里很多问题,仔细看其实都在追同一件事:一个值从哪儿来,经过了什么处理,最后流到哪儿去。这类问题有一个共同的名字:data flow analysis。
比如,"用户输入是否未经转义就流到了SQL查询",是data flow问题;"一个引用是否可能在未赋值的路径上被解引用",也是data flow问题。前者关心安全,后者关心健壮性,但工具底下要做的事情很像:沿着程序的执行路径,把值的状态变化跟一遍。
在静态代码安全分析里,data flow analysis最常见的形态之一,就是taint analysis。思路很直接:给程序里的值贴上标签,看标签怎么随程序执行流动、合并、传下去。tainted、safe、html-escaped、sql-safe这类状态,都可以表示成标签。
这个模型看起来很简单。要拿它做真正的静态分析工具就不简单了。
标签远不止"污染/安全"两种状态。一个真正能工作的引擎,要用标签编码数据的来源、经过的变换、已通过的验证——本质上是在给安全领域的知识做形式化建模。
二元标签:最简单的污点模型
先看一个最经典的Web应用场景:从HTTP请求里拿用户输入,拼字符串递给数据库,中间不做任何sanitize或参数化。这就是一条标准的SQL注入路径。换成data flow的语言:不可信的值从哪儿进入程序,经过什么操作,最后流到哪个危险API。
怎么追这条路径?关键的一点在这里:我们其实不需要知道一个变量的具体值是什么,只要知道它是不是来自不可信的外部输入。把这个属性贴到值上,让它随着赋值、传参、返回一起流动,就能在不运行程序的情况下把整条路径追完。
具体怎么贴?值来自外部输入时,给它标上tainted(不可信)。标签随data flow流动:tainted值未经sanitize到达危险API,就报漏洞;没有tainted到达,就不报。这就是二元标签模型。
外部输入点叫Source,data flow流到的危险API叫Sink。来看代码:
String name = request.getParameter("name"); // Source: name → tainted
String query = "SELECT * FROM users WHERE name = '" + name + "'";
Statement stmt = conn.createStatement();
stmt.execute(query); // Sink: tainted值流入 → 报告SQL注入
request.getParameter()读的是HTTP请求里的用户输入,外部完全可控,所以返回值打tainted。stmt.execute()直接执行SQL语句,外部输入混进去就有注入风险,所以它是Sink。tainted随data flow流到Sink,引擎报SQL注入。
那标签到底放在哪儿?不是真的附在程序运行时的值上。分析引擎在自己内存里维护一套影子状态:每个变量对应一个标签,记的不是值本身,是值的安全属性。可以理解成与程序变量空间平行的一张映射表。
传播规则也很简单。数据从A流向B(赋值、传参、返回值),B继承A的标签。多个值合并(比如字符串拼接),结果的标签按"或"语义合并:任一输入tainted则输出tainted。回到上面例子:name是tainted,"SELECT ... " + name把safe常量和tainted拼起来,按"或"语义query也是tainted;query传入stmt.execute(),tainted就跟着到了Sink。整个过程就是标签沿着data flow一步步往下走。
当然,从Source出发的data flow不一定都是漏洞。如果数据到达Sink之前被适当处理过,比如SQL用参数化绑定、XSS用HTML转义、或者通用的白名单校验,路径就是安全的。这类能清除tainted标签的操作叫做Sanitizer。Source、Sink、Sanitizer,是taint analysis的三个基本角色。
换一个具体场景演示Sanitizer的作用——HTML body上下文的XSS用escapeHtml做转义。整条Source-Sanitizer-Sink data flow如下:

上半未经sanitize,TAINTED一路传到Sink报漏洞;下半经过escapeHtml,标签翻成SAFE后Sink放行。
这套思路的理论根基其实很早。1976年Denning1提出了用格结构追踪信息流动的理论框架;1989年Perl在语言层面内置了taint mode,自动追踪外部输入并禁止直接用在危险操作上。之后各种语言和平台陆续出现了实现,到今天几乎所有主流静态代码分析引擎都把taint analysis作为核心能力。只是早就不再停留在二元标签这种最简形态了。
但二元标签有个明显的局限:它把所有漏洞类型压成了同一个维度。一个值要么tainted要么不是,分不清对哪种漏洞危险。
举个legacy项目里常见的例子:手写的escapeHtml(input),只把<、>、&替换成HTML实体,漏掉了引号。这就麻烦了。
对HTML正文的XSS来说,<script>已被转义成<script>,这个值是safe的。但单引号'一字未动:拼进"WHERE name = '" + escaped + "'"仍能break出SQL string literal造成注入;拼进<img src='...' onerror='...'>属性里也能闭合引号造成attribute context的XSS。
二元标签下没法表达"对XSS安全但对SQL不安全"这种中间地带。这个escapeHtml要么整体标为Sanitizer(SQLi和attribute XSS漏报),要么不标(HTML正文XSS误报)。
安全这件事本身就是多维的——不同漏洞类型各有危险路径和sanitize要求。一个bit装不下这些维度,这是二元模型的天花板。
传播机制:标签沿CFG流动到稳定
在引入多元之前,先看下面这套底层基础设施——标签怎么在程序里流动。二元用它,多元也用它。分析引擎并不真的"运行"程序——它在自己的内存里维护一套影子状态:模拟程序运行时的栈和局部变量表,但每个槽位放的是标签而不是真实值。这个影子状态叫做Frame,每个程序点对应一个Frame,记录该点处所有变量和栈位的标签状态。一个关键的设计选择:标签直接替代了值本身——引擎完全不需要知道name变量装的是"rm -rf /"还是"hello world",只关心它的标签是什么。整个程序的运行时语义被压缩进了标签语义。
这套机制在工业实现上长什么样?以Spotbugs为例,它的edu.umd.cs.findbugs.ba.Frame<T>是泛型的:T可以替换成不同的标签类型,做不同种类的分析。把上一节那段SQL注入代码喂给Spotbugs,引擎处理String name = request.getParameter("name")这一行时,实际跑的是一段字节码序列:INVOKEVIRTUAL getParameter()先把返回值压到operand stack上,紧接着的ASTORE_n指令把它存进name对应的局部变量槽位(实例方法0号通常是this,name具体占哪一号取决于方法签名和之前已声明的局部变量)。ASTORE_n执行后,name所在的Frame槽位在三种分析下的状态对照:
ASTORE_n执行后,`name`所在Locals槽位的内容(T为泛型参数):
null analysis : T = IsNullValue → MAYBE_NULL
type analysis : T = Type → String
taint analysis : T = Taint → TAINTED (插件如findsecbugs)

同一段字节码序列执行后,name所在Locals槽位从⊥变成[T];T换三种填法(IsNullValue/Type/Taint)跑出三种analysis结果。Frame结构不变,标签语义可插拔。
Frame的结构、CFG的切分、汇合点的合并规则全部不变,变的只是槽位里那个T的具体形态。Frame是通用的基础设施,标签是可插拔的语义——同一套传播机制可以驱动多种data flow分析。下一节多元体系会把taint analysis的T升级成更精细的标签集合,但跑的还是这套Frame基础设施。
Frame解决了"标签放在哪里",但标签要真正动起来还得有路径。程序流不是线性的——有分支、循环、方法调用——所以传播也不能是线性扫描。引擎先把方法切成CFG(控制流图):基本块是一段没有分支的连续指令序列,块之间用有向边连接。块内传播很机械:每条字节码指令按JVM规范定义的栈操作语义更新Frame——ALOAD把局部变量的标签复制到栈顶,ASTORE反过来,方法调用按规则消费参数标签产生返回值标签。块内是顺序扫描,没有复杂度——所有的复杂度集中在块的边界,主要是两种情况:分支汇合(多条边汇入同一块)和循环回边(边指回前驱块)。
先看分支汇合。来自不同前驱块的Frame需要在汇合点合并,引擎不知道运行时会走哪条分支,所以保守地合并所有可能性——只要某条路径上name带了TAINTED,合并后就保留。形式上是取并集(OR)。这就是静态分析的根本立场——当无法判断时,往最危险的方向倒。代价是可能误报(实际运行时走的是另一条不会污染的分支),收益是不漏报。
再看循环回边。回边让后继块的合并结果反过来影响前驱块的输入:考虑一个while循环,循环体里给变量赋了一个tainted值——第一轮分析时,循环入口处的合并还没收到来自循环体的污染状态;第二轮回边把这个状态带回入口,合并必须重做。引擎反复迭代,直到所有Frame都不再变化——达到不动点。收敛的保证来自标签的可能值有限(TAINTED/SAFE只有两种),加上每轮合并只增不减(OR的天性),迭代必然在有限步内稳定。

左:循环CFG结构(Header是merge点,back-edge把Body的状态送回去合并);右:三轮迭代到不动点的状态演进——第2轮Header吃到back-edge的TAINTED,第3轮等于第2轮,达成stable。
多元标签:对安全知识的形式化建模
回到二元节末尾那个escapeHtml的例子。一个bit只能记"是否tainted"这一件事,但要追踪的远不止——还有"是否HTML转义"、"是否SQL转义"、"是否attribute引号转义"。这些事彼此独立,bit装不下。
所以自然引入多元标签的概念:把每个值上附加的"一个bit",换成"一个标签集合"。原来的tainted/safe打散成多种细分标签,XSS_TAINTED、SQL_TAINTED、PATH_TAINTED等各自独立、互不重叠。一个值可能同时带多种标签(比如request.getParameter()返回的string,HTTP参数对所有这些漏洞类型都不可信),也可能只带某一种。引擎维护的影子状态没变,依然是与变量空间平行的映射表,变的是每个槽位里放的东西——从一个bit变成一个集合。
集合化之后,标签按"标记风险"和"标记安全"两类自然分开。风险标签描述"这个值带有XX风险",XSS_TAINTED、SQL_TAINTED这类,标记数据来源的不可信,由Source添加;安全标签描述"这个值已对XX风险做过处理",XSS_HTML_ESCAPED、SQL_PARAM_BOUND这类,标记数据已建立的安全承诺,由Sanitizer添加。两类标签在同一个集合里共存。Sanitizer的实际做法有两种:往集合里追加安全标签(如XSS_HTML_ESCAPED),或直接从集合里移除对应的风险标签(如把XSS_TAINTED从集合中删除)——前者保留完整的处理轨迹便于审计,后者让集合保持精简,Fortify等成熟引擎两种都支持。判定漏洞的责任随之交给Sink,每个Sink声明自己的触发契约,形如has(XSS_TAINTED) AND NOT has(XSS_HTML_ESCAPED)——"我看到对应的风险标签,且没看到对应的安全标签"。"什么算漏洞"从二元模型下引擎隐式的is_tainted查询,变成sink端可精确陈述的契约表达式。

同一段代码,二元和多元representation的三stage对照。二元在Sanitizer后整体翻SAFE丢失SQL/PATH维度,到SQL Sink漏报;多元在原集合上追加XSS_HTML_ESCAPED但保留所有风险标签,Sink契约正确检出。
Sanitizer同步精细化。它不再做tainted → safe的整体跃迁,而是声明自己加哪些安全标签——escapeHtml(input)只加XSS_HTML_ESCAPED,不动SQL_TAINTED,也不加XSS_ATTR_ESCAPED。回到二元节那个困境,多元体系下同一个值流向三个sink得到三个独立判定:
String input = request.getParameter("name"); // {XSS_TAINTED, SQL_TAINTED, ...}
String escaped = escapeHtml(input); // 在原集合上追加{XSS_HTML_ESCAPED}
response.write("<div>" + escaped + "</div>"); // 契约: has(XSS_TAINTED) AND NOT has(XSS_HTML_ESCAPED) → 不报
stmt.execute("WHERE name='" + escaped + "'"); // 契约: has(SQL_TAINTED) AND NOT has(SQL_PARAM_BOUND) → 报SQL注入
response.write("<img src='" + escaped + "'>"); // 契约: has(XSS_TAINTED) AND NOT has(XSS_ATTR_ESCAPED) → 报attribute XSS
XSS_HTML_ESCAPED只能消除HTML body context的XSS契约,对SQL契约和attribute XSS契约毫无作用。三个sink给出三个独立判定——漏报和误报同时被消除。
多元体系的复杂性还会延伸到传播机制。上一节讲的"分支汇合取并集"在多元下不再够用——考虑一个if/else,一个分支调用了escapeHtml,另一个没调用。如果两类标签都简单取并集,XSS_HTML_ESCAPED会被保留,sink契约不触发,漏洞漏报:
String input = request.getParameter("name"); // {XSS_TAINTED, SQL_TAINTED, ...}
String x;
if (someCondition()) {
x = escapeHtml(input); // {XSS_TAINTED, SQL_TAINTED, XSS_HTML_ESCAPED}
} else {
x = input; // {XSS_TAINTED, SQL_TAINTED}
}
// 汇合点: x → {XSS_TAINTED, SQL_TAINTED} (风险标签取并集 + 安全标签取交集)
response.write("<div>" + x + "</div>"); // 契约触发, 报XSS漏洞
正确的做法是风险标签和安全标签合并方向相反:风险标签取并集(只要某条路径带了XSS_TAINTED,合并后保留),安全标签取交集(只有所有路径都处理过,才算处理)。这是上一节"对sink最不利方向"原则在多元体系下的具体展开——风险标签往多里靠(多则更易触发sink),安全标签往少里靠(少则更易触发sink)。
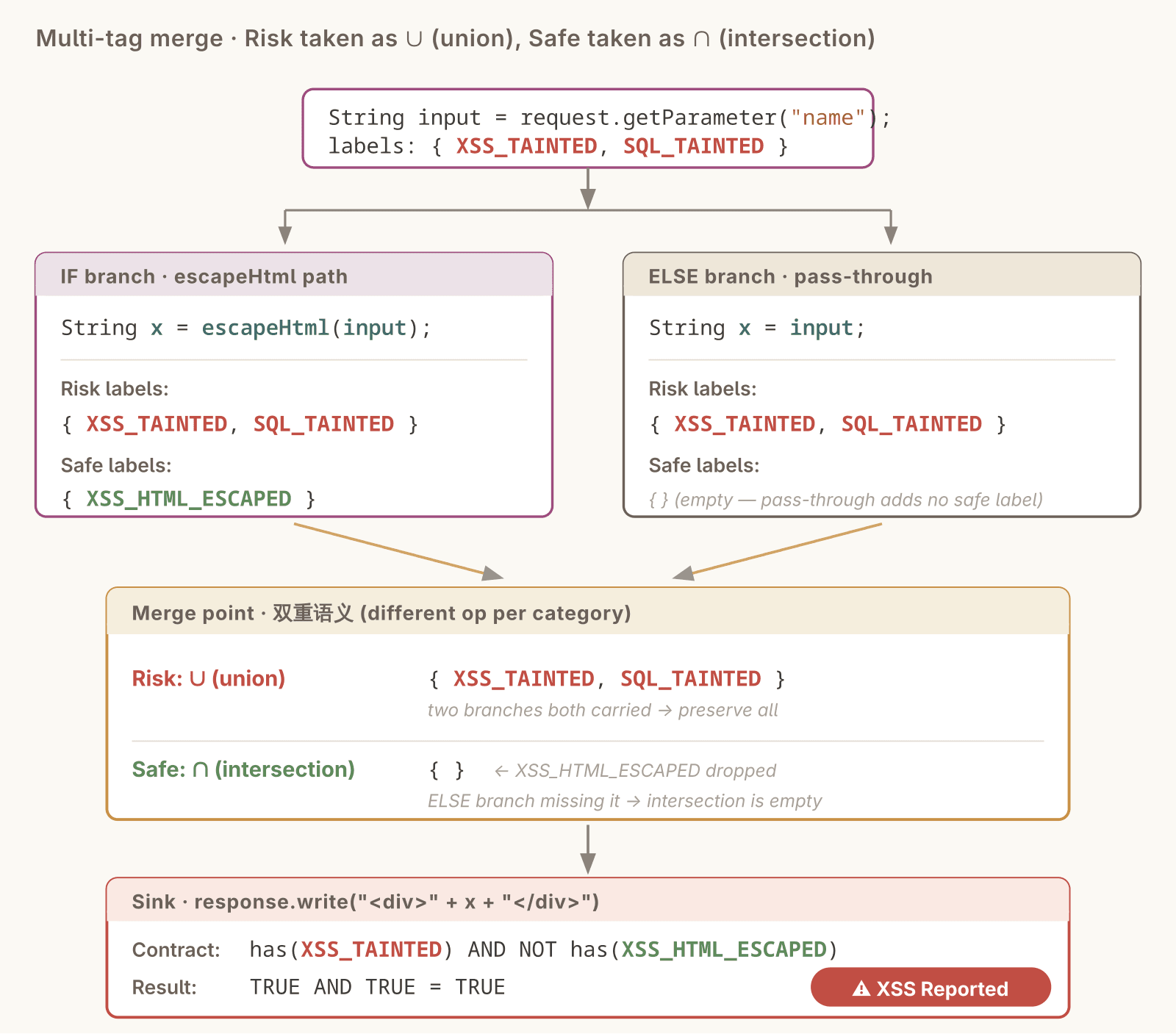
if/else两路Frame合并时,风险标签和安全标签方向相反:风险取并集(XSS_TAINTED两路都有→保留),安全取交集(XSS_HTML_ESCAPED只在if路有→丢弃)。Sink收到带XSS_TAINTED但不带XSS_HTML_ESCAPED的集合,契约触发报漏洞。
多元体系撑得起这一切,是因为标签从一维变成了多维——而安全领域本身就是多维的:漏洞类型、处理方式、context各自独立。二元标签把这些维度压成一个bit,漏报误报二选一;多元标签让每个维度都有自己的标签、自己的添加移除、自己的契约。
收尾
Taint analysis有一个无法绕开的盲区:主流实现只追踪显式data flow。考虑一个例子:
boolean secret = ...; // sensitive source
int y = 0;
if (secret) y = 1; // 没有secret到y的直接赋值
log(y); // sink: 输出0或1,等于泄漏一比特secret
y的值取决于secret,但不是通过赋值传递,而是通过分支条件——这种control dependence引擎追不到。理论上把control dependence纳入传播规则就能覆盖这种implicit information flow(Denning 1976的原始信息流框架即是),但误报爆炸让工程实现几乎都放弃了。
难就难在控制依赖的范围。真实代码里几乎每个变量都能沿某个if或while的条件追回到外部input——比如if (config.flag) result = ...,result也跟着flag染上tainted(哪怕flag其实是hard-coded benign配置)。这类传播一打开,污染像油墨在水里散开,最后几乎全程序变量都tainted,真假漏洞混在一起。
学术上的尝试——JIF(Java Information Flow)、Paragon、flow-sensitive type system等——让程序员显式标注哪些控制依赖可以泄漏,把传播裁回去。代价是要写大量标注,工程使用门槛太高,因此没有成为主流SAST的常用路线。
回头看,taint analysis是更通用机制的一个instance:换个维度就是另一种分析——{NULL, MAYBE_NULL, NON_NULL}是空指针分析,{ENCRYPTED, PLAINTEXT}是加密状态追踪,{RESOURCE_OPENED, RESOURCE_CLOSED}是资源泄漏检测。底层那套(Frame、CFG、汇合点合并、不动点迭代)都不动,动的只是标签维度。这就是"程序语义建模"。
Footnotes
Dorothy E. Denning, "A Lattice Model of Secure Information Flow", Communications of the ACM, vol. 19, no. 5, pp. 236-243, May 1976. ↩